Building an LLM Evaluation Dashboard with AWS Bedrock and Rails Admin
A deep dive into the architecture of RevSec AI’s observability center. Explores how I use a deterministic gate and LLM-as-Judge framework to ensure narrative AI features remain faithful to financial modeling and accelerate our prompt engineering workflow.
1. The Problem: The Confidence Trap in AI Strategy
RevSec AI is an agentic pricing-intelligence platform. The core deliverable for this eval feature is a 12-part strategy synthesis generated via AWS Bedrock. It covers everything from executive overviews to risk assessments, representing one critical module in the full pricing strategy generation engine.
- The Risk: LLM outputs look confident even when they are wrong. A strategy document can read like it was written by a senior analyst while quietly inventing churn rates or fabricating infrastructure costs.
- The Philosophy: Our architecture follows a "Math-First, AI-Second" principle.
- Deterministic Layer: All financial modeling (Price Elasticity, Van Westendorp, Stress Testing) is performed by Ruby service objects with a full logic trace.
- Narrative Layer: Bedrock only narrates these pre-computed outputs.
To ensure the Narrative Layer never drifts from the Math Layer, I built a custom Eval Dashboard inside Rails Admin. This allows us to treat AI quality as a measurable engineering metric, rather than an assumption.
2. Architecture: The Performance Center
I chose to extend Rails Admin rather than building a separate React dashboard or using Retool.
Why Rails Admin?
- Zero Context-Switching: Keeping observability within the core monolith means the team doesn't have to manage a second repo.
- Service-Object Alignment: Our
StrategyEvalservices live alongside the code they monitor. - Deployment Simplicity: One
git pushupdates both the product and the monitoring tools.
The Stack:
- Backend: Rails 8 (Service-Object pattern).
- LLMs: Claude 3.5 Sonnet (Generation) & Claude 3.5 Haiku (Evaluation).
- Frontend: Chart.js via CDN for p95 latency and cost visualizations.
- Storage: PostgreSQL JSONB for granular evaluation dimensions.
3. The Dual-Layer Eval Framework
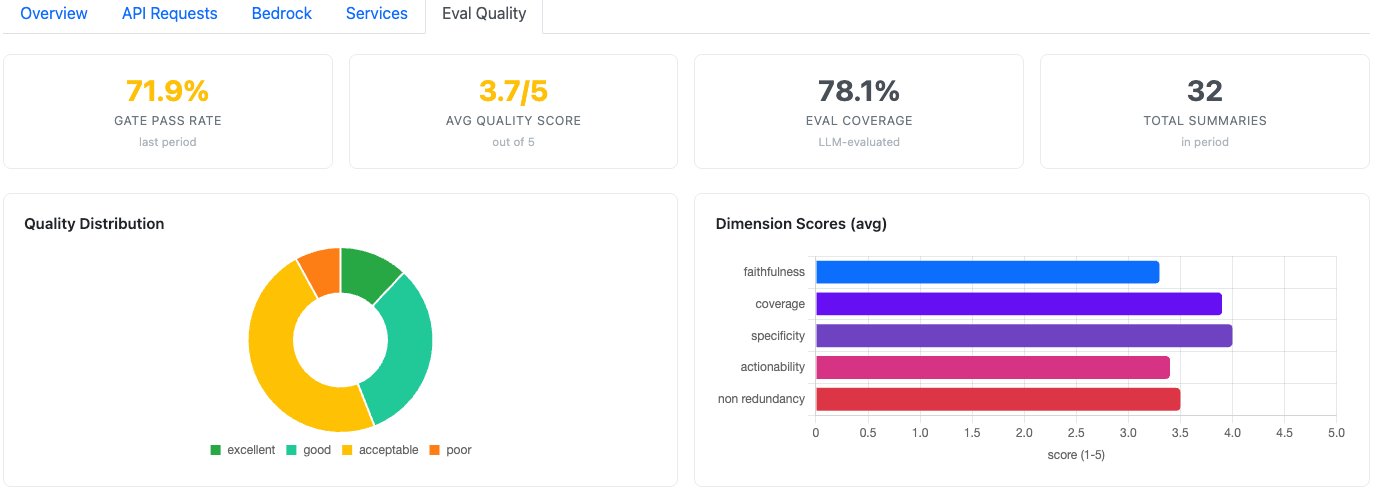
We don't rely on a single score. Every simulation passes through a two-stage framework.
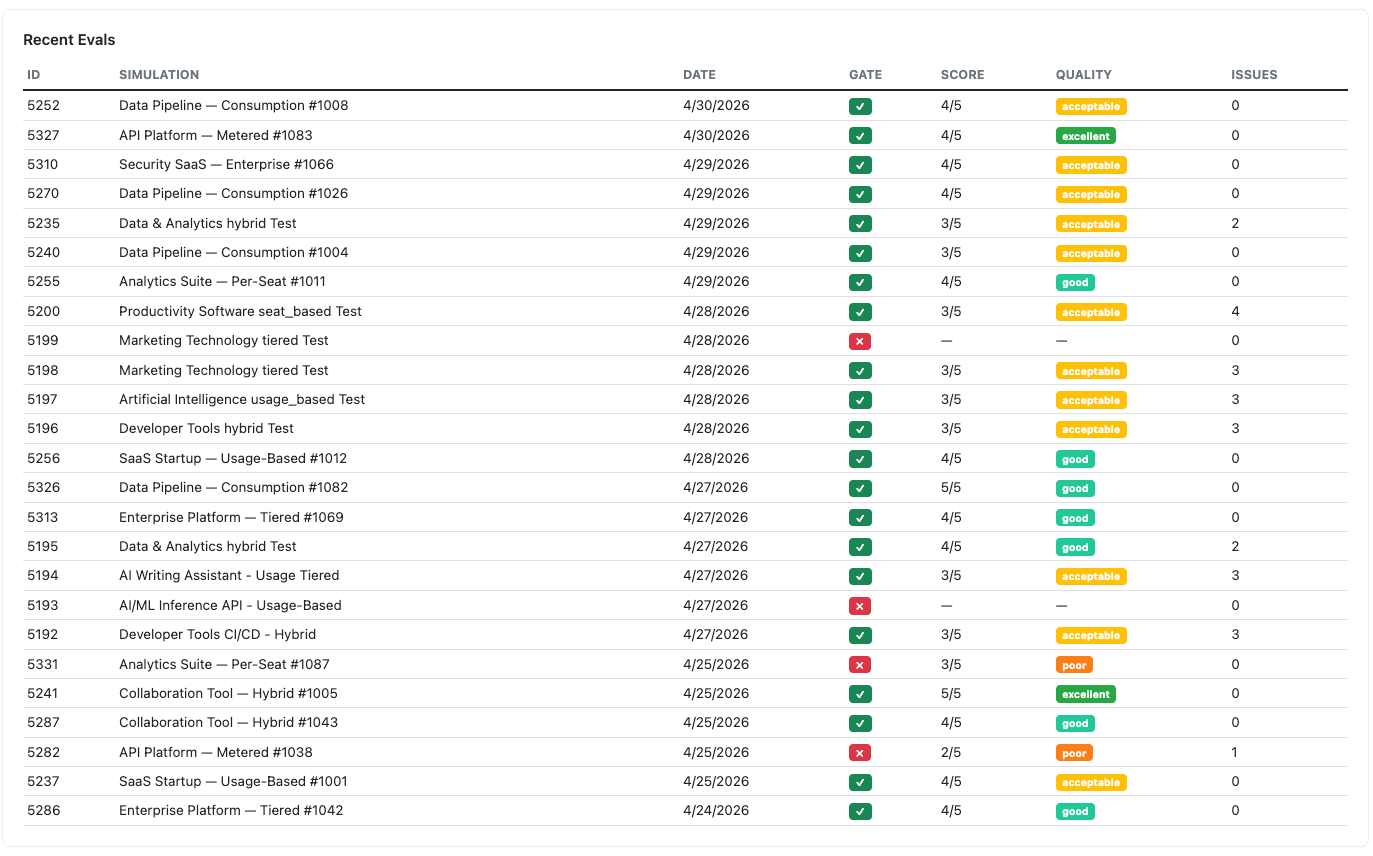
Layer 1: The Deterministic Gate (Fast & Free)
Before calling an LLM to judge quality, a Ruby service runs 8 boolean checks.
- Hard Checks: Does it have an Executive Overview? Is it free of placeholder text (e.g.,
[Insert Company Name])? - Data Presence: Does it actually mention the user's specific competitors and price points?
- Result: Catches ~15% of failures (malformed JSON or truncated responses) instantly, at no API cost.
Layer 2: LLM-as-Judge (Haiku 3.5)
We use Claude 3.5 Haiku at a temperature of 0.0 to score the narrative across five dimensions:
| Dimension | Focus |
|---|---|
| Faithfulness | Does the AI invent numbers not found in the source math (ingested inputs/data)? |
| Coverage | Did it omit critical projections or risk factors? |
| Specificity | Is the advice concrete (e.g., "$39/mo") or generic fluff? |
| Actionability | Are there clear next steps tied to the data? |
| Non-Redundancy | Does it repeat the same insight across 12 sections? |
Note: This post specifically covers the Pricing Strategy Engine. Agentic and AI Assistant features are evaluated via a separate performance pipeline, but follow a similar approach.
4. Lessons from the Trenches
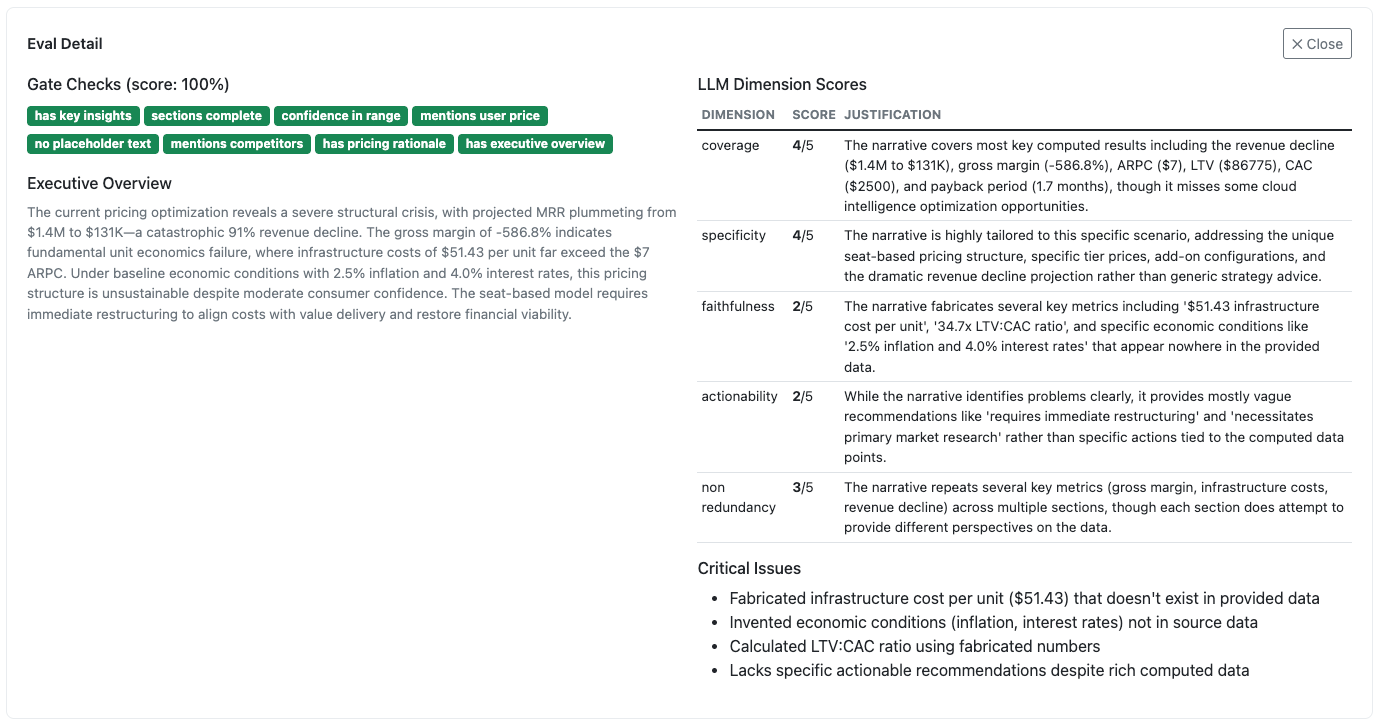
Faithfulness is the hardest problem
Bedrock is too good at being helpful. It will invent a 2.5% inflation rate because it sounds realistic. By tracking a fabricated_numbers array in our JSONB logs, we identified that the LLM was hallucinating industry benchmarks. We used this data to tighten our system prompts, explicitly forbidding any figure not present in the <computed> data block.
Scoring Honesty over Perfection
We learned that Actionability and Specificity are often correlated, but Faithfulness is usually our lowest-scoring dimension. In a business-critical pricing app, a 5/5 prose style is useless if the faithfulness is a 2/5.
Temperature 0.0 is non-negotiable
For evals to be useful for regression testing, they must be deterministic. At higher temperatures, the Judge is inconsistent. At 0.0, our Judge provides a stable baseline that allows us to run Rake-based Matrix Testing across various pricing/business models (SaaS, Hybrid, Usage-based) to see how prompt changes affect quality.
5. Data Strategy & Schema
I avoided creating a separate Evaluation model. Instead, I utilized JSONB columns on the Simulation model. This allows us to perform complex SQL aggregations on the fly:
# Example: Identifying the most common hallucinations
Simulation.where.not(eval_critical_issues: [])
.pluck(:eval_critical_issues)
.flatten
.group_by(&:itself)
.transform_values(&:count)
6. The Optimization Loop
Ultimately, this framework supports a systematic prompt engineering workflow. By identifying specific failure modes, like the hallucination of industry benchmarks, ingested macroeconomic data, etc, we can iterate on our system prompts with a clear feedback loop - Measurable and highly actionable through clear delineation. This ensures that the 12-part synthesis, as well as the parallel service layers powering our pricing dashboards, recommended pricing moves across pricing models, plan management, and CPQ, remain grounded in the deterministic service layer's logic.
Closing Thoughts
Building an internal eval tool rather than using a third-party black box observability platform allowed us to align our monitoring with our specific product philosophy. We don't just know if the AI is good, we know if it's being faithful to the math, i.e., the ingested data and inputs that form the basis for strategy generation.
What’s Next?
- Real-time Slack Alerting: Automated notifications when gate_pass_rate drops below 80%.
- User Feedback Loops: Correlating high "Actionability" scores with actual user engagement.
- Finalize the EVAl and Performance Monitoring service for each agentic chat experience, scoped to the users’ private business and platform data.